November 12, 2016
I love Apache Spark. Not just becacuse of it’s capability to adapt to so many use-cases, but because it’s one of shining star in the Distributing Computing world, has a great design and superb community backing.
However, one of the features I’d want enhancement in is, the way it processes the streams. Spark processes the streams in a micro-batch manner i.e, you set a time interval (could be any value), and Spark will process the events collected in that interval, in batch. This is where Apache Flink comes in!
Apache Flink is often comapred with Spark. I feel Spark is far ahead of Flink, not just in technology; but even community backing of Spark is very big, compared to Flink.
Anyways, this post is not about comparing them, but to provide a detailed example of processing a RabbitMQ’s stream using Apache Flink.
Step 1: Install Rabbitmq, Apache Flink in your system. Both installations are very straightforward.
Step 2: Start Rabbitmq server
rabbitmq-server &
Step 3: Create an exchange in the rabbitmq. Go to http://localhost:15672 (In my example, I’m binding a queue to the exchange. You can directly use a queue, but make sure to make corresponding changes in the code)
Step 4: Clone the repo from here: (will be explaining the codes inline)
git clone https://github.com/rootcss/flink-rabbitmq.git
Step 5: It’s built with maven. (Java) So, build it using:
mvn clean package
Step 6: Once built, You’re all set to run it now:
flink run -c com.rootcss.flink.RabbitmqStreamProcessor target/flink-rabbitmq-0.1.jar
Step 7: Check the logs at:
tail -f $FLINK_HOME/log/*
and Flink’s dashboard at:
http://localhost:8081/
Step 8: Now, you can start publishing events from the RabbitMQ’s exchange and see the output in the logs.
Note that, I am not using any Flink’s Sink here (writing into the logs). You can use a file system like HDFS or a Database or even Rabbitmq (on a different channel ;))
Code Explanation
(This version might be a little different from the code in my repo. Just to keep this concise)
// Extend the RMQSource class, since we need to override a method to bind our queue
public class RabbitmqStreamProcessor extends RMQSource{
// This is mainly because we have to bind our queue to an exchange. If you are using a queue directly, you may skip it
@Override
protected void setupQueue() throws IOException {
AMQP.Queue.DeclareOk result = channel.queueDeclare("simple_dev", true, false, false, null);
channel.queueBind(result.getQueue(), "simple_exchange", "*");
}
public static void main(String[] args) throws Exception {
// Setting up rabbitmq's configurations; ignore the default values
RMQConnectionConfig connectionConfig = new RMQConnectionConfig.Builder()
.setHost("localhost").setPort(5672).setUserName("rootcss")
.setPassword("password").setVirtualHost("/").build();
// below ones are pretty intuitive class names, right?
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Finally adding Rabbitmq as source of the stream for Flink
DataStream<String> dataStream = env.addSource(new RMQSource<String>(connectionConfig,
"simple_dev",
new SimpleStringSchema()));
// Accepting the events, and doing a flatMap to calculate string length of each event (to keep the things easy)
DataStream<Tuple2<String, Integer>> pairs = dataStream.flatMap(new TextLengthCalculator());
// action on the pairs, you can plug your Flink's Sink here as well.
pairs.print();
// Start the execution of the worker
env.execute();
}
And, here is the beautiful web interface of Apache Flink:
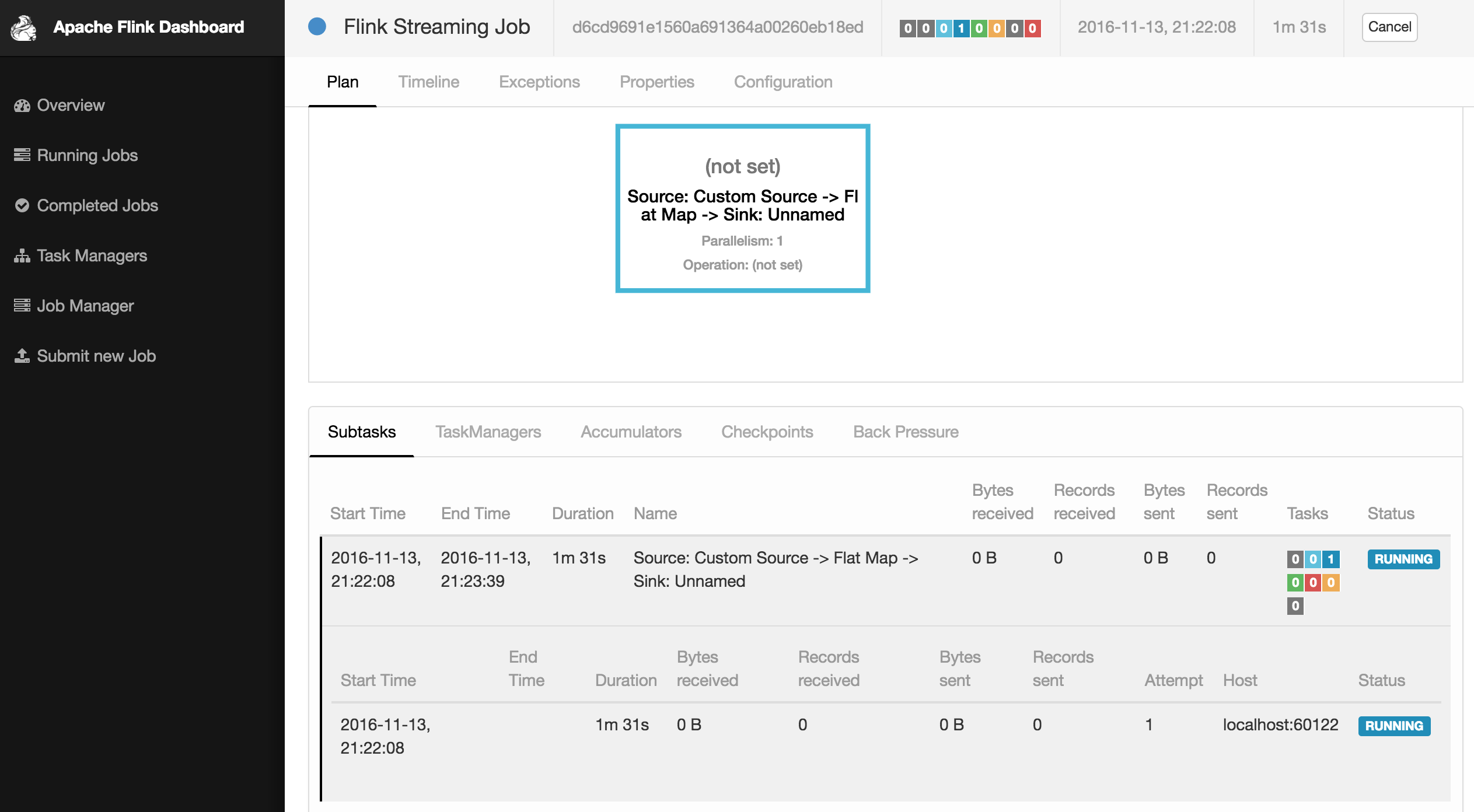
In the next post, I will be explaining how I bomarded events on both Spark & Flink, to compare their endurance. Just for fun :-D
Stay Tuned!
Tags: Flink Rabbitmq Data Engineering Big Data
Tweet