March 26, 2019
At Simpl, we use pandas heavily to run a bunch of our machine learning models many of them implemented with scikit-learn. We’ve been growing rapidly and sometime back, one of the models crashed with python’s MemoryError exception. We were pretty sure that the hardware resources are enough to run the task.
What is the MemoryError? It’s an exception thrown by interpreter when not enough memory is available for creation of new python objects or for a running operation.
The catch here is that, it doesn’t necessarily mean “not enough memory available”. It could also mean that, there are some objects that are still not cleaned up by Garbage Cleaner (GC).
To test this, I wrote a very small script:
arr = numpy.random.randn(10000000, 5)
def blast():
for i in range(10000):
x = pandas.DataFrame(arr.copy())
result = x.xs(1000)
blast()
Below is the distribution (Memory usage w.r.t Time) before the program crashed with MemoryError exception.
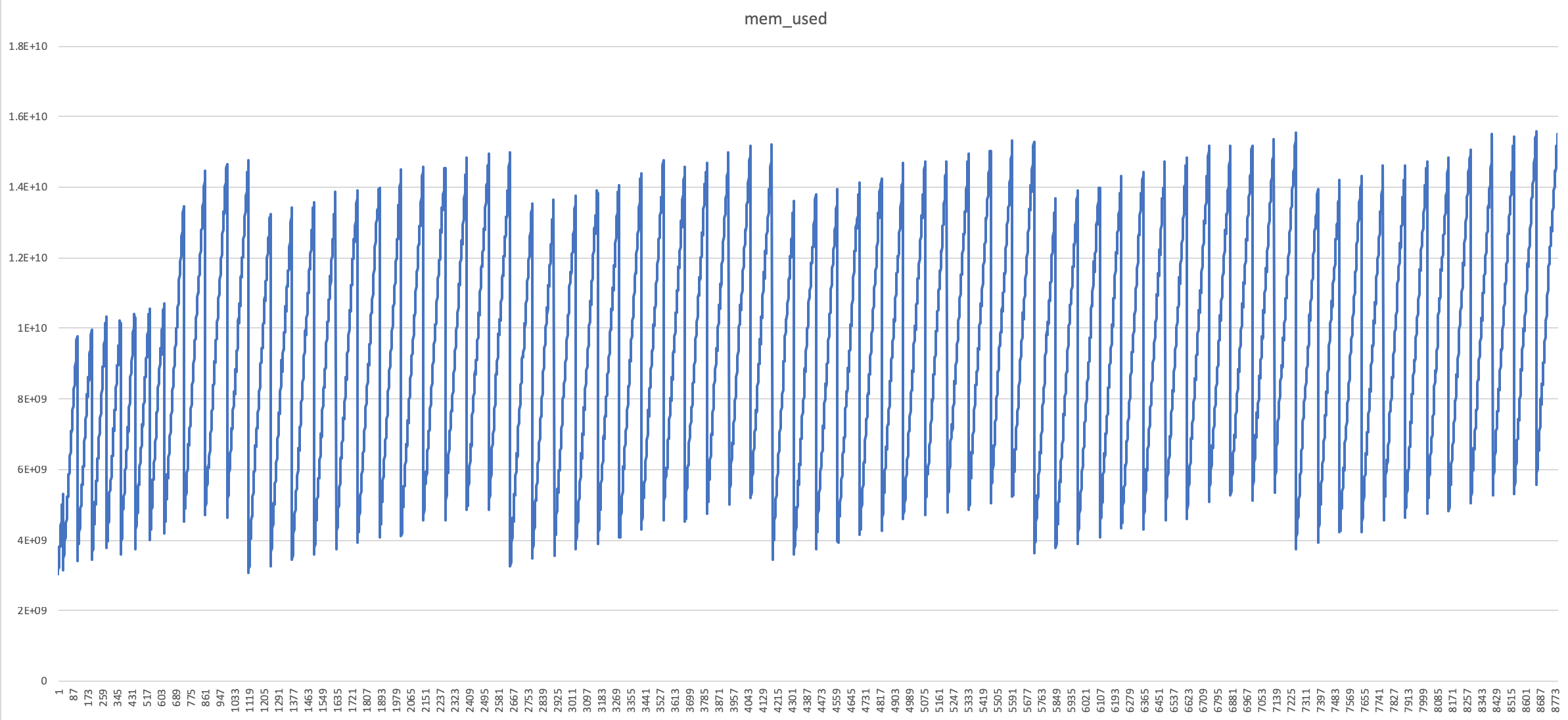
The GC seems to be working fine, but it’s not able to clean up the objects as fast as it’s required in this case.
What’s the issue?
Python’s default implementation is CPython (github) which is implemented in C. The problem was this bug; in the implementation of malloc in glibc (which is GNU’s implementation of C standard library).
Issue Details:
M_MXFAST is the maximum size of a requested block that is served by using optimized memory containers called fastbins. free() is called when a memory cleanup of allocated space is required; which triggers the trimming of fastbins. Apparently, when malloc() is less than M_MXFAST, free() is not trimming fastbins. But, if we manually call malloc_trim(0) at that point, it should free() up those fastbins as well.
Here is a snippet from malloc.c’s free() implementation (alias __libc_free). (link)
p = mem2chunk (mem);
if (chunk_is_mmapped (p)) /* release mmapped memory. */
{
/* See if the dynamic brk/mmap threshold needs adjusting.
Dumped fake mmapped chunks do not affect the threshold. */
if (!mp_.no_dyn_threshold
&& chunksize_nomask (p) > mp_.mmap_threshold
&& chunksize_nomask (p) <= DEFAULT_MMAP_THRESHOLD_MAX
&& !DUMPED_MAIN_ARENA_CHUNK (p))
{
mp_.mmap_threshold = chunksize (p);
mp_.trim_threshold = 2 * mp_.mmap_threshold;
LIBC_PROBE (memory_mallopt_free_dyn_thresholds, 2,
mp_.mmap_threshold, mp_.trim_threshold);
}
munmap_chunk (p);
return;
}
Therefore, we need to trigger malloc_trim(0) from our python code written above; which we can easily do using ctypes module.
The fixed implementation looks like this:
from ctypes import cdll, CDLL
cdll.LoadLibrary("libc.so.6")
libc = CDLL("libc.so.6")
libc.malloc_trim(0)
arr = numpy.random.randn(10000000, 5)
def blast():
for i in range(10000):
x = pandas.DataFrame(arr.copy())
result = x.xs(1000)
libc.malloc_trim(0)
blast()
In another solution, I tried forcing the GC using python’s gc module; which gave the results similar to above method.
import gc
arr = numpy.random.randn(10000000, 5)
def blast():
for i in range(10000):
x = pandas.DataFrame(arr.copy())
result = x.xs(1000)
gc.collect() # Forced GC
blast()
The distrubution of Memory usage w.r.t Time looked much better now, and there was almost no difference in execution time. (see the “dark blue” line)
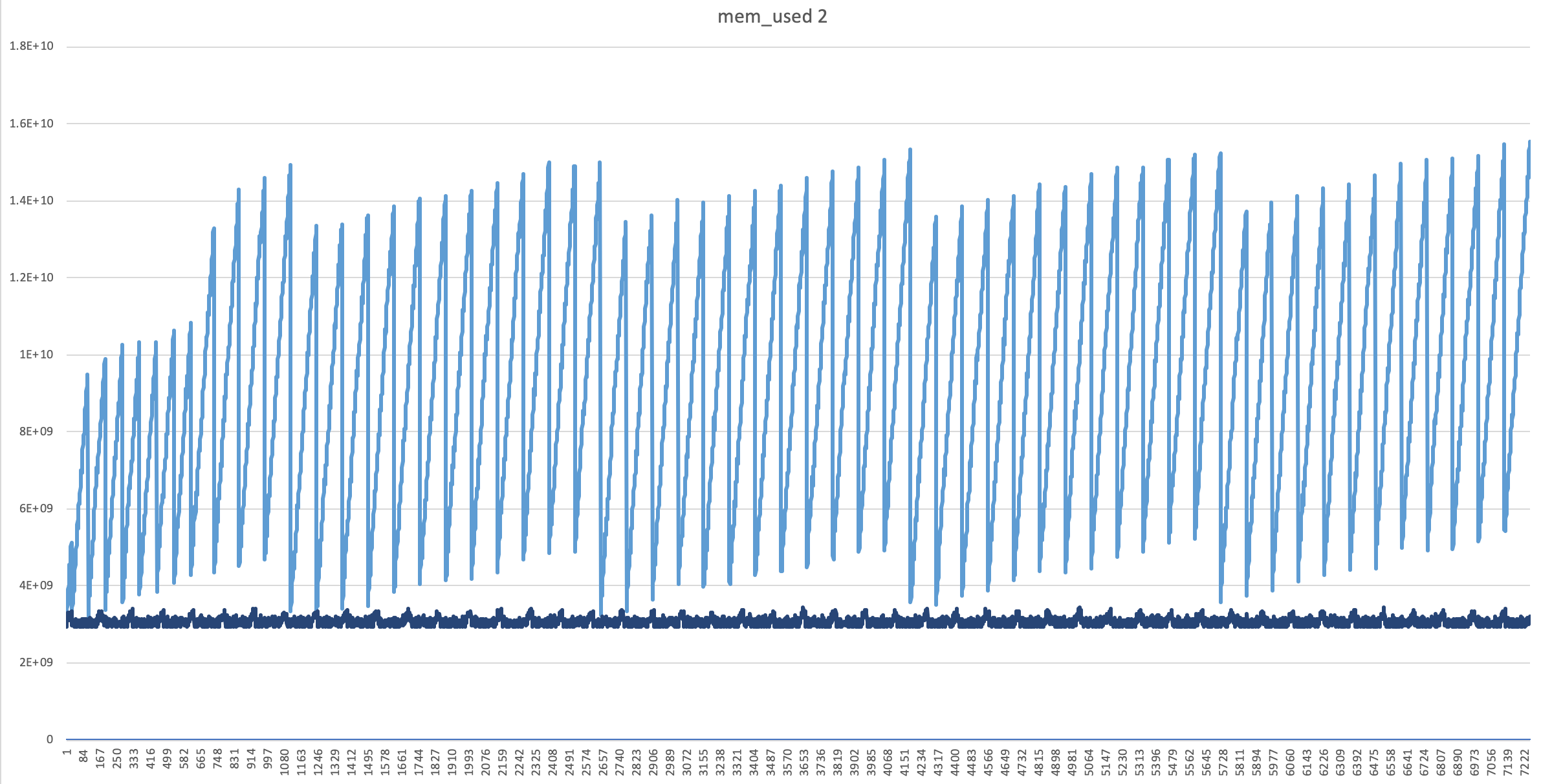
Similar cases, References and other notes:
- Even after doing
low_memory=Falsewhile reading a CSV usingpandas.read_csv, it crashes withMemoryErrorexception, even though the CSV is not bigger than the RAM. - Explanation of malloc(), calloc(), free(), realloc() deserves a separate post altogether. I’ll post that soon.
- Similar reported issues:
- https://github.com/pandas-dev/pandas/issues/2659
- https://github.com/pandas-dev/pandas/issues/21353
Tags: Python Pandas
Tweet